Configure Timeouts
Theoretically there could be a read timeout if lots of data is being transported between ElasticSearch and the Axon.ivy Engine. You can raise the timeout times in the ivy.yaml and check if that solves the connectivity problem:
https://developer.axonivy.com/doc/latest/EngineGuideHtml/configuration.html#ref_Elasticsearch

Check Index Health
Elastic Search has a REST API. Therefore, one can easily list all indexes and check its health state. If the health of an index is in state RED, the Axon.ivy Engine will be unable to communicate with it.
On the Engine host you can list indexes via: http://localhost:19200/_cat/indices?v
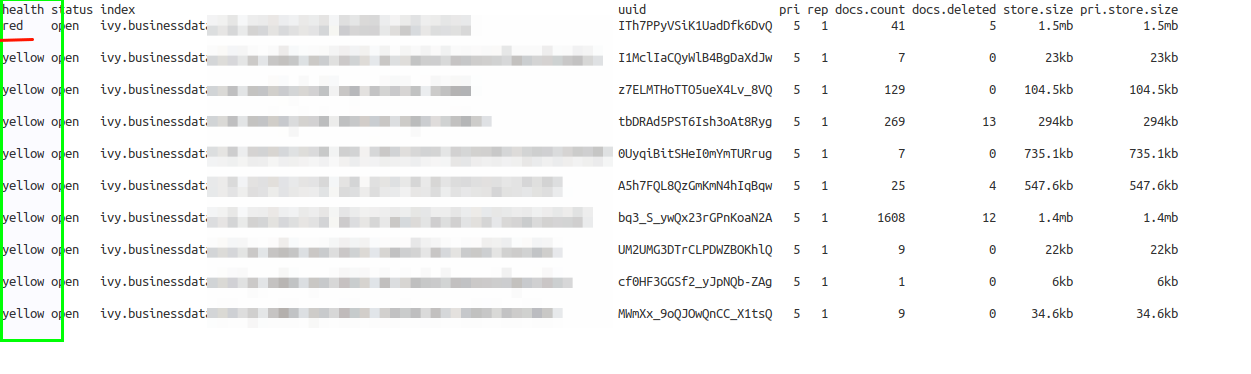
Elastic Logs
Once you are aware that an Index is RED, you can analyze the elastic search logs. They can be found in the file system engineDir/elasticsearch/logs.
Scan these logs for messages that relate to the red index. This can be a tricky task when the interesting logs are splitted into multiple files. I like to do such analysis via the well known grep binary from the unix stack.
grep -C 10 ivy.businessdata-myIndexName *.log
Here is a sample which exposes the lack of diskspace as the cause of the problem:
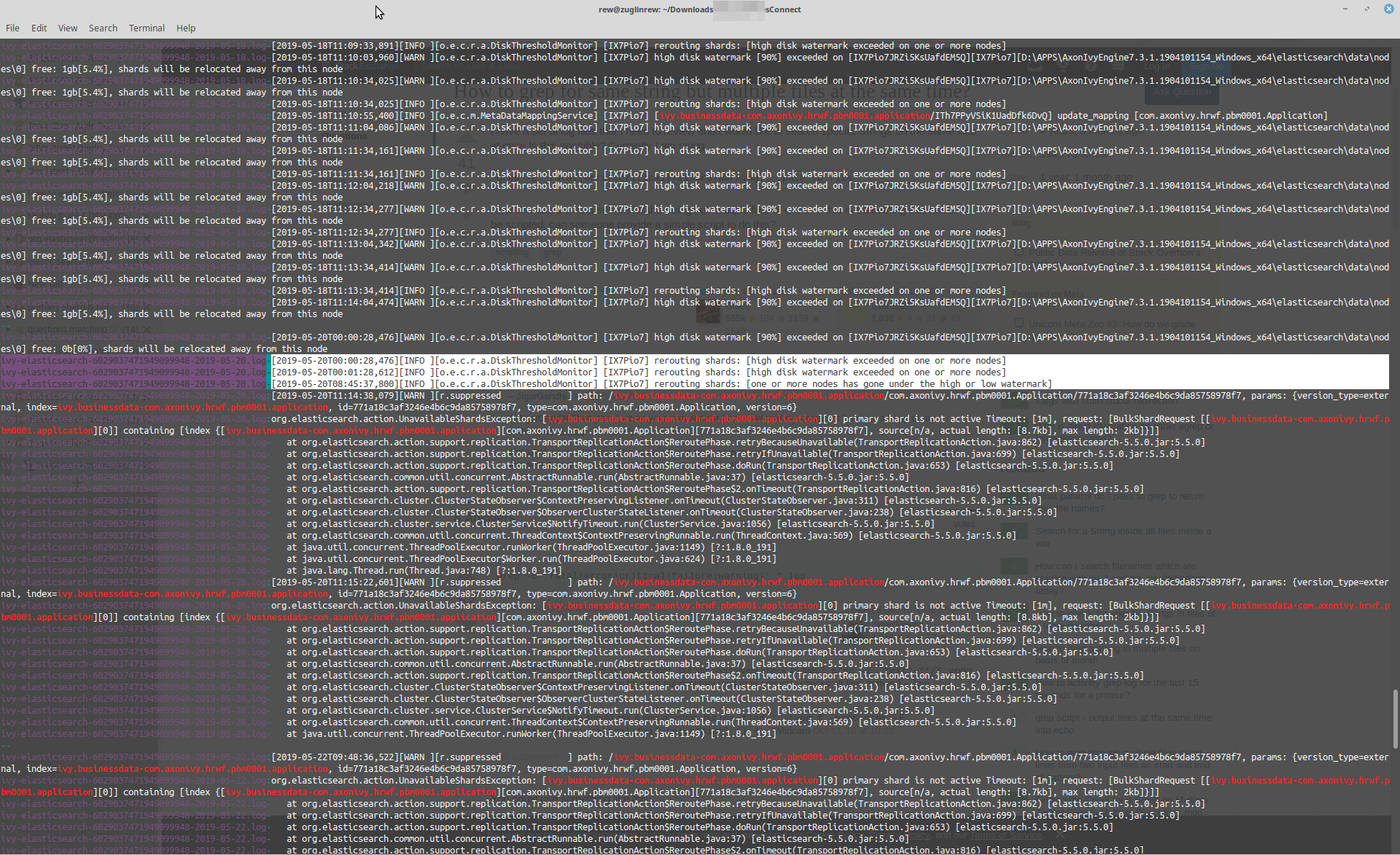
In the shown case the latest elastic search logs contain org.elasticsearch.action.UnavailableShardsExceptions whenever the engine tries to write into that RED index. However, walking back in the logs clearly shows that elasticsearch index just ran out of space before.
[2019-05-23T13:22:42,633][WARN ][r.suppressed ] path: /ivy.businessdata-com.axonivy.hrwf.pbm0001.application/com.axonivy.hrwf.pbm0001.Application/771a18c3af3246e4b6c9da85758978f7, params: {version_type=external, index=ivy.businessdata-com.axonivy.hrwf.pbm0001.application, id=771a18c3af3246e4b6c9da85758978f7, type=com.axonivy.hrwf.pbm0001.Application, version=6}
org.elasticsearch.action.UnavailableShardsException: [ivy.businessdata-com.axonivy.hrwf.pbm0001.application][0] primary shard is not active Timeout: [1m], request: [BulkShardRequest [[ivy.businessdata-com.axonivy.hrwf.pbm0001.application][0]] containing [index {[ivy.businessdata-com.axonivy.hrwf.pbm0001.application][com.axonivy.hrwf.pbm0001.Application][771a18c3af3246e4b6c9da85758978f7], source[n/a, actual length: [8.7kb], max length: 2kb]}]]
at org.elasticsearch.action.support.replication.TransportReplicationAction$ReroutePhase.retryBecauseUnavailable(TransportReplicationAction.java:862) [elasticsearch-5.5.0.jar:5.5.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$ReroutePhase.retryIfUnavailable(TransportReplicationAction.java:699) [elasticsearch-5.5.0.jar:5.5.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$ReroutePhase.doRun(TransportReplicationAction.java:653) [elasticsearch-5.5.0.jar:5.5.0]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) [elasticsearch-5.5.0.jar:5.5.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$ReroutePhase$2.onTimeout(TransportReplicationAction.java:816) [elasticsearch-5.5.0.jar:5.5.0]
at org.elasticsearch.cluster.ClusterStateObserver$ContextPreservingListener.onTimeout(ClusterStateObserver.java:311) [elasticsearch-5.5.0.jar:5.5.0]
at org.elasticsearch.cluster.ClusterStateObserver$ObserverClusterStateListener.onTimeout(ClusterStateObserver.java:238) [elasticsearch-5.5.0.jar:5.5.0]
at org.elasticsearch.cluster.service.ClusterService$NotifyTimeout.run(ClusterService.java:1056) [elasticsearch-5.5.0.jar:5.5.0]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:569) [elasticsearch-5.5.0.jar:5.5.0]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_191]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_191]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_191]
answered
27.05.2019 at 03:21

Reguel Werme... ♦♦
9.4k●3●19●58
accept rate:
70%